J’ai suivi un webinaire Run:ai (Amériques) sur l’inférence ML et son autoscaling sur AWS. À l’époque j’étais plongé dans des projets GPU/containers, mais l’inférence en prod ressemblait encore à « quelqu’un a SSH sur une machine ». La session a été utile parce qu’elle cadrait l’inférence comme un problème de capacité et d’ordonnancement — pas seulement d’export de modèle. English version.
Pourquoi j’ai regardé
L’entraînement fait le buzz ; l’inférence coûte cher tant que l’endpoint reste ouvert. Sur AWS, ça passe souvent par EKS, des groupes de nœuds GPU, du scaling type HPA/KEDA, et une finance qui demande pourquoi l’utilisation est à 12 % pendant que la latence grimpe. Run:ai se présente comme couche de contrôle Kubernetes pour clusters GPU partagés : files équitables, visibilité sur la consommation, politiques pour que l’inférence ne soit pas affamée par le batch — ou l’inverse.
Je n’ai pas déployé Run:ai ensuite ; ces notes servent pour du travail plateforme plus tard (quotas, observabilité, vocabulaire de refacturation). Pour d’autres notes de conférence en 2022, voir Snowflake Data-for-Breakfast ; côté appli ML, recherche vectorielle / RAG.
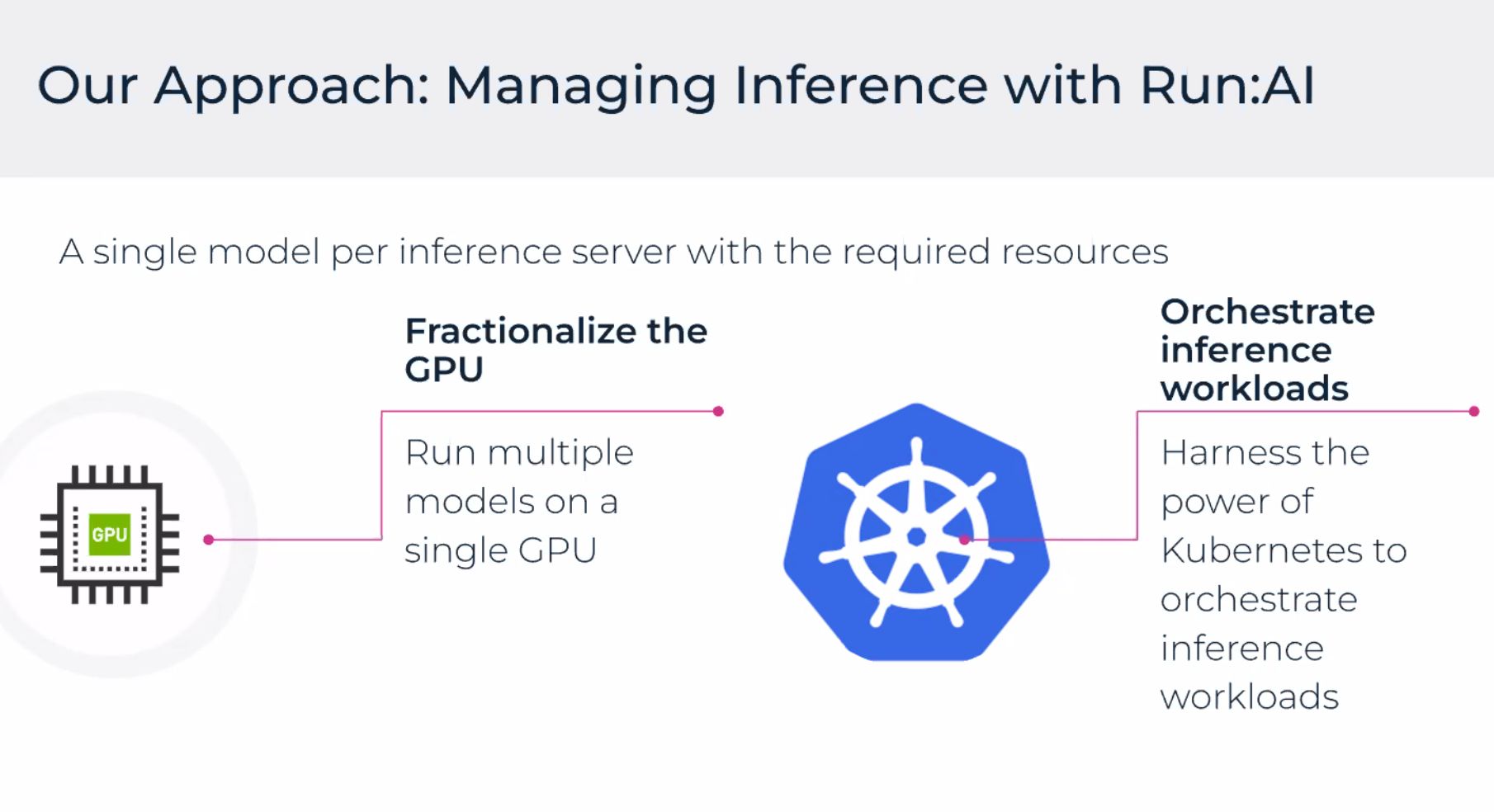
Ce que Run:ai optimise (en bref)
Les équipes achètent des GPU chers, traitent Kubernetes comme du CPU générique, puis s’étonnent des pics de latence ou des nœuds vides. Run:ai ajoute placement, priorisation et reporting sur les jobs GPU — entraînement, fine-tuning et services d’inférence dans le même parc. Sur AWS, ça rejoint la façon dont vous provisionnez les instances et exposez les modèles (conteneurs, réplicas).
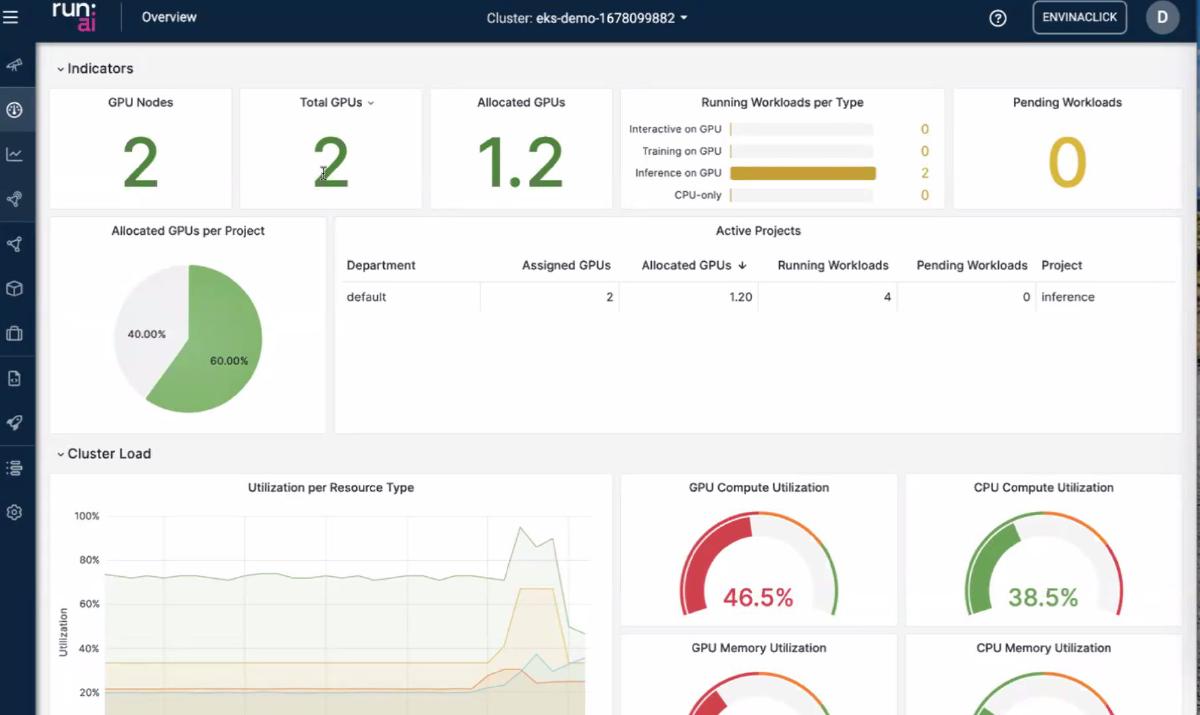
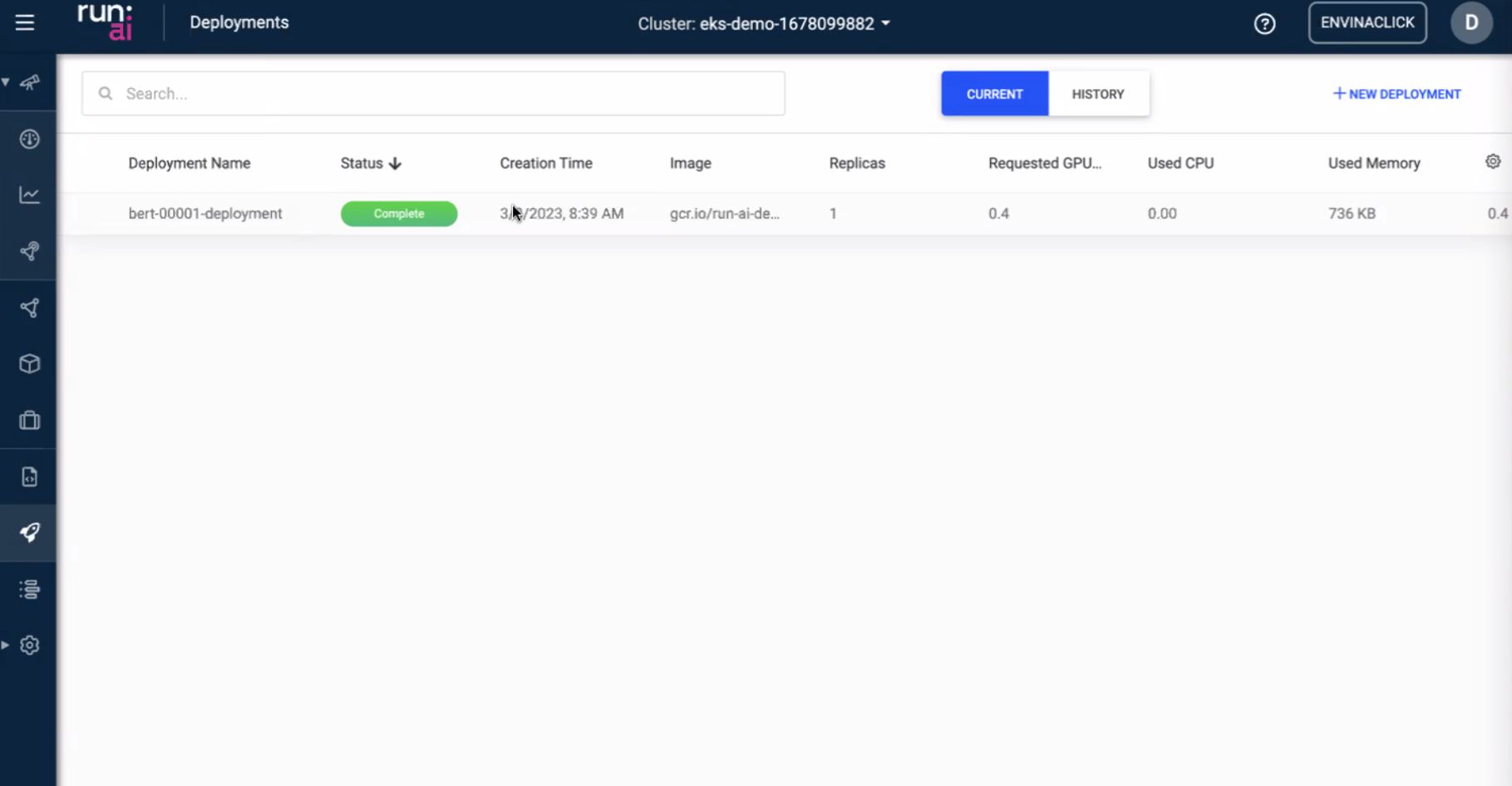
Tableau de bord — jobs et utilisation
Les slides UI = le « cerveau ops » : quoi tourne, quoi attend, et si les GPU sont utilisés ou seulement réservés.
- Liste / statut des jobs — réplicas d’inférence et batch comme objets visibles, pas seulement des pods anonymes.
- Utilisation — l’écart alloué vs utilisé est là où l’argent fuit ; le tableau de bord vise les propriétaires de plateforme.
- Deuxième vue — découpe cluster vs équipe/projet (utile pour défendre des quotas).
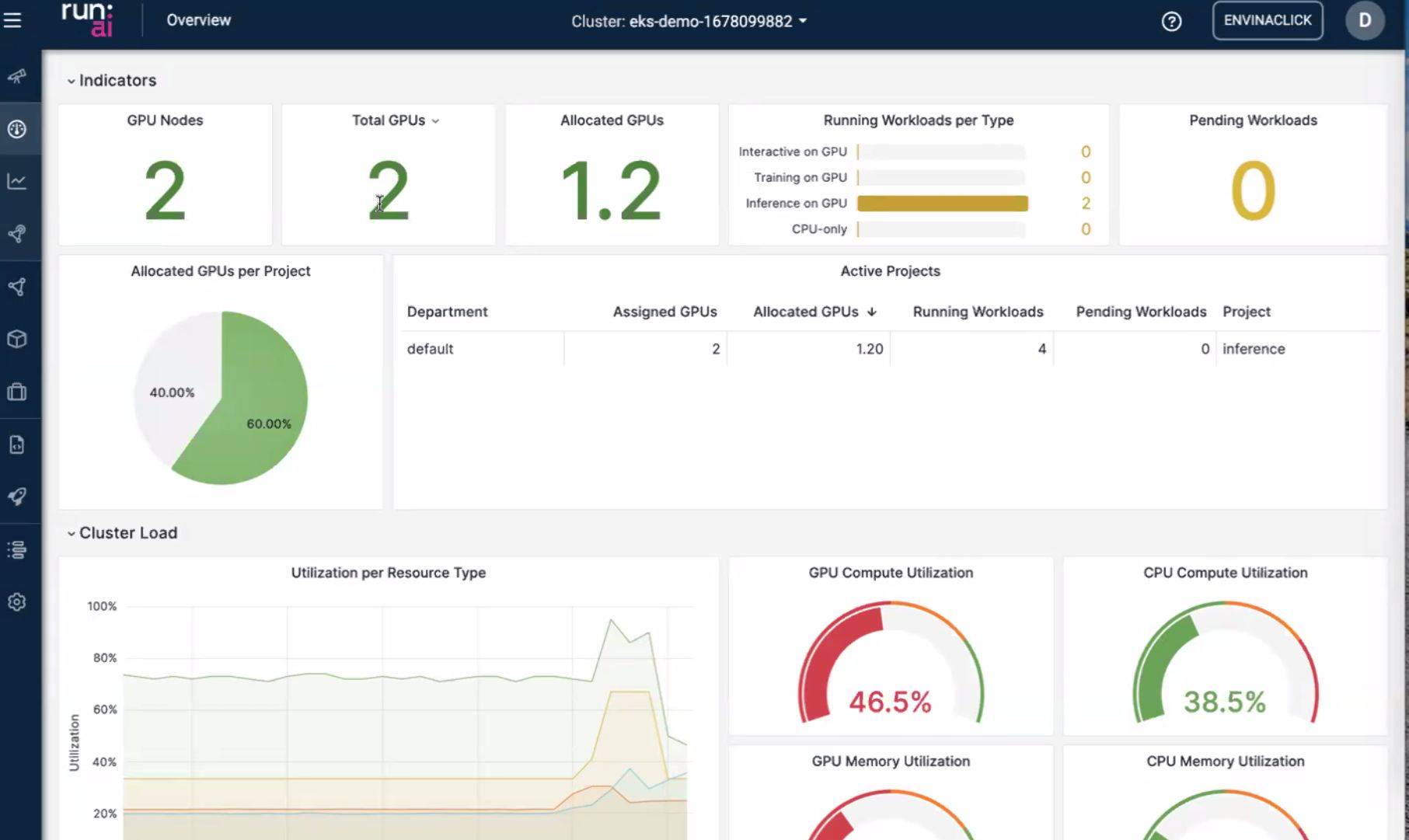
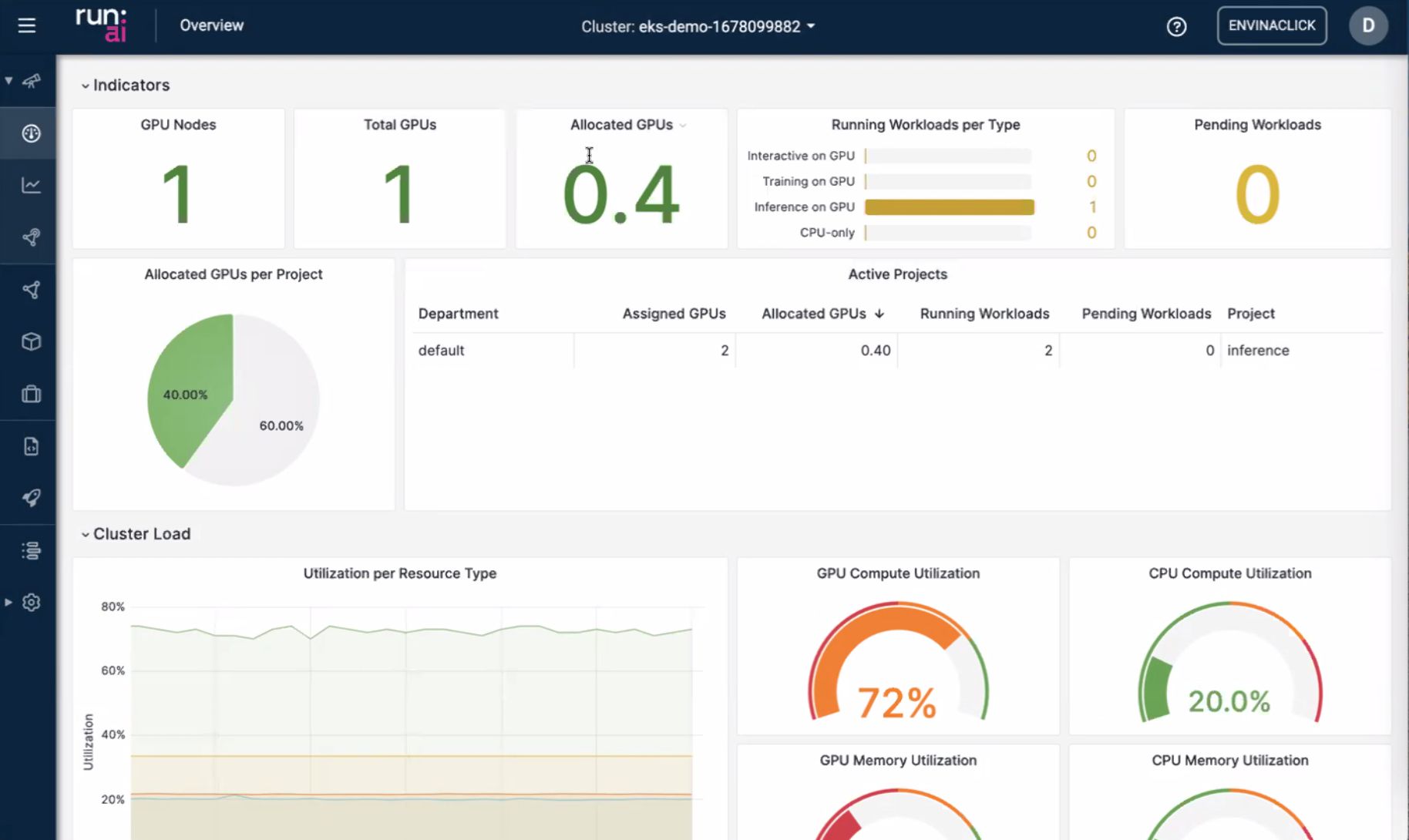
Bilan perso : si je ne peux pas répondre « qui tient le GPU ? » en moins d’une minute, ce n’est pas une plateforme d’inférence — c’est un serveur partagé déguisé.
CLI — automatisation et pipelines
La CLI reprend les objets de l’UI : soumettre des charges, inspecter les files, brancher les pipelines. L’autoscaling d’inférence n’est pas que du HPA : il faut aussi des déploiements versionnés, des canaries et du teardown quand un modèle est retiré.
Patterns évoqués :
- CI construit l’image → CLI/API enregistre une charge d’inférence avec bornes CPU/GPU/RAM.
- Règles de scale sur profondeur de file, SLO de latence ou plages horaires.
- Politiques cluster côté plateforme ; artefacts modèle côté équipes ML.
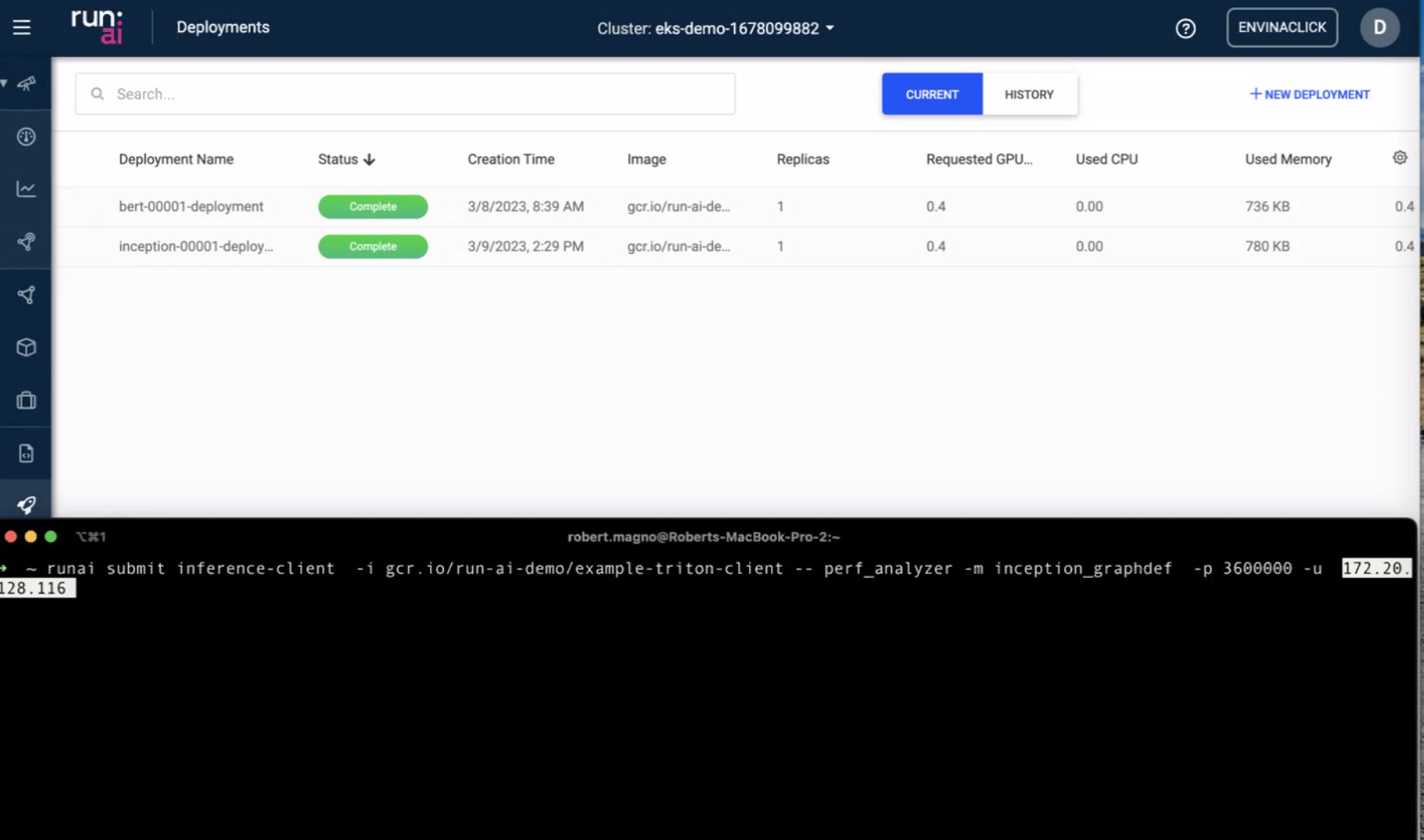
Modèles — packaging et multi-instance
Vue centrée modèle : un service logique, N réplicas. C’est la différence entre « un pod sur un g5 » et « un service qui survit à la perte d’un nœud ».
Le slide multi-instance = scale horizontal quand le trafic monte — dupliquer les workers, répartir sur les nœuds, garder la planification sensible à la mémoire GPU (gros LLM vs petit modèle CV).

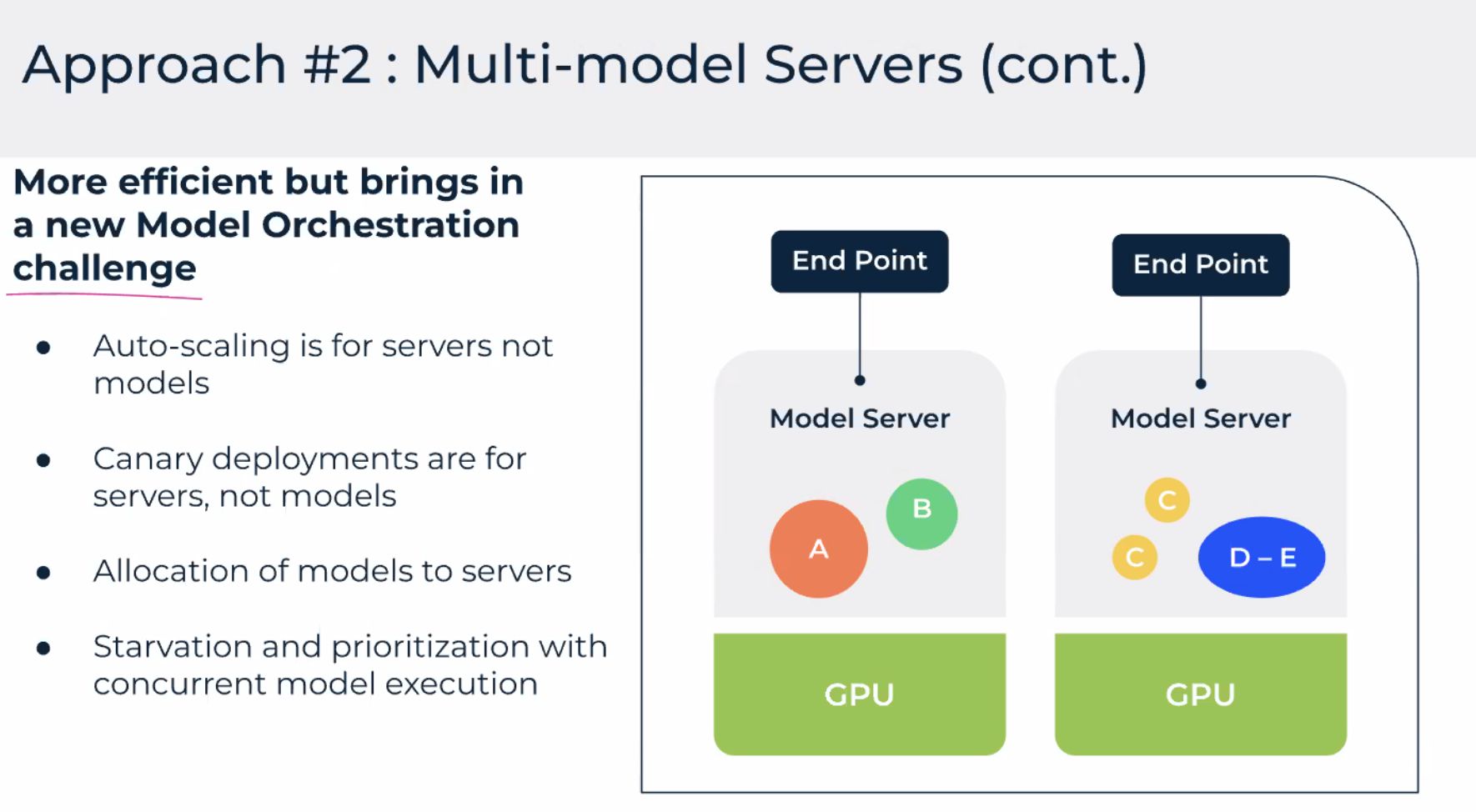
Questions notées :
- Cold start au montage des poids (S3/EFS) ?
- Plafond de réplicas limité par la fragmentation GPU ?
- Scale-down : drain des requêtes ou arrêt brutal (SLO vs coût) ?
Workloads — files, plafonds, équité
Gestion des workloads : quotas par équipe, priorités, préemption, fenêtres horaires. C’est le contrat social quand 10 équipes partagent 8 GPU.
- L’inférence veut souvent socle stable + burst ; l’entraînement veut de longs blocs.
- Une bonne plateforme montre la position dans la file et une estimation de départ — pas seulement un échec après six heures.
Infrastructure — serveurs et facture
Vue serveurs / cluster : nœuds Kubernetes, types d’instances, santé. Sur AWS, à recouper avec :
- Groupes de nœuds (g5.xlarge vs cartes plus grosses, mix d’instances).
- Cluster autoscaler vs remplissage d’abord par le scheduler Run:ai.
- Spot pour le batch tolérant aux pannes vs on-demand pour l’inférence sensible à la latence.
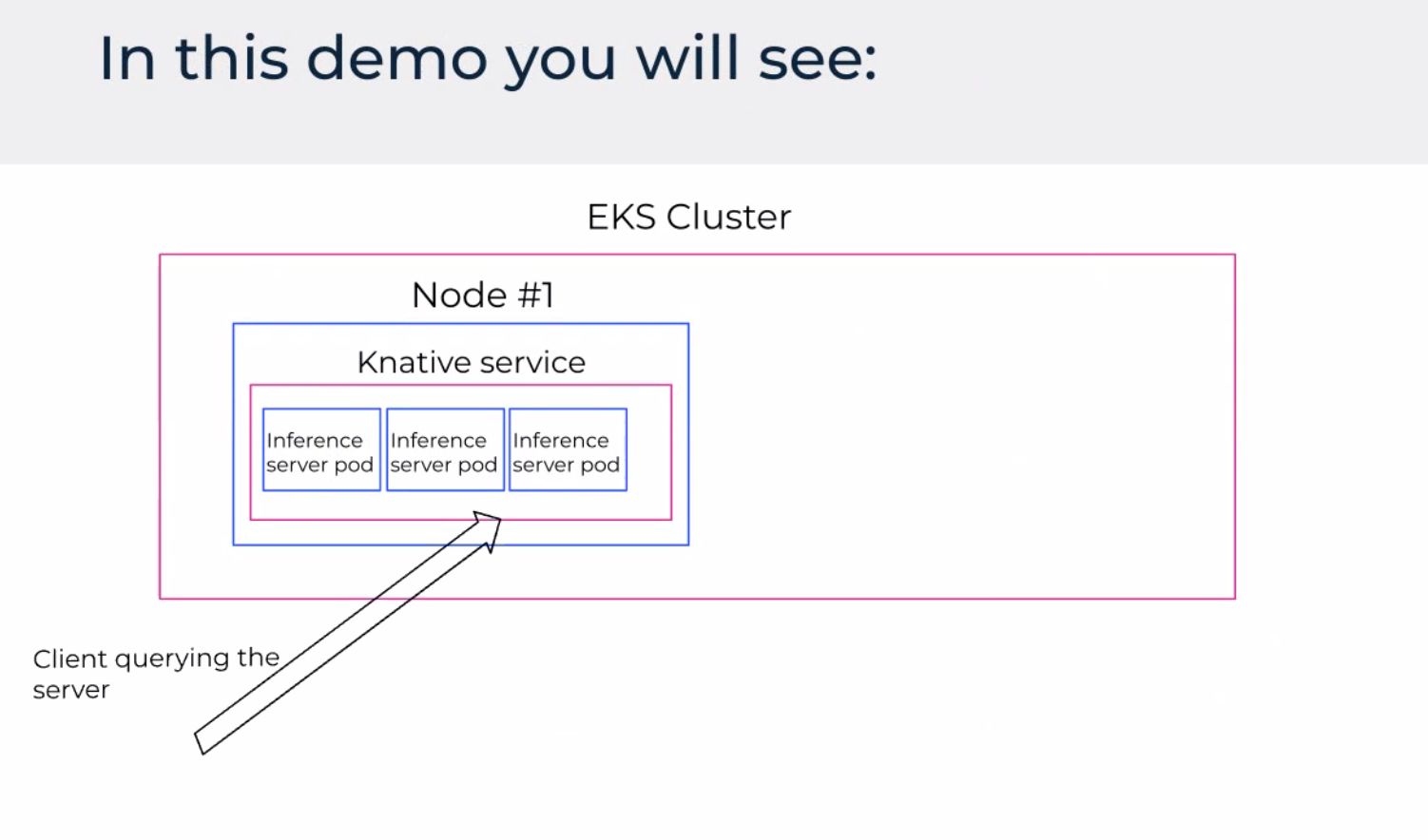
Démo et défis (le slide honnête)
La démo enchaînait déploiement ou scale d’inférence, mouvement du tableau de bord, parité CLI. Le slide défis valait le détour :
| Défi | Impact |
|---|---|
| Faible utilisation GPU | Payer des cartes idle avec des files d’attente |
| Voisins bruyants | Pics training qui tuent les SLO d’inférence |
| Trou d’observabilité | Prometheus voit des pods, pas « latence modèle v3 » |
| Lag d’autoscaling | Nouveaux nœuds GPU lents ; réplicas inutiles si non planifiables |
| Attribution des coûts | Finance par produit ; labels et quotas dès le jour 1 |
| Colle MLOps | Registry, monitoring et scheduler = trois outils |

Ce que j’en retirerais aujourd’hui
- Pools nœuds inference séparés (ou taints) avant de mélanger avec le training.
- SLO d’abord (p95, temps max en file), puis signaux d’autoscaler.
- Labels refacturation (
team,model,env) dès le départ. - Traiter le partage GPU comme décision produit : cartes dédiées vs quotas partagés.
Références
- Documentation Run:ai
- AWS Marketplace (chercher « Run:ai »)
- Planification GPU Kubernetes
Notes de septembre 2022 ; noms produit et chemins AWS peuvent avoir changé depuis.