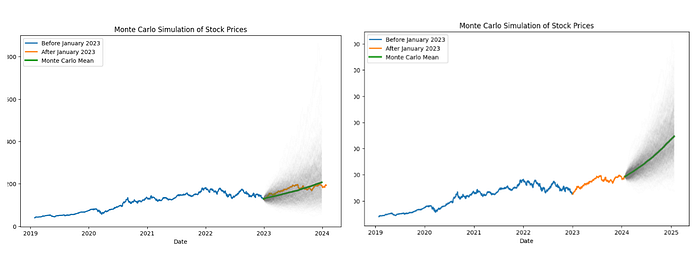
En trading, on raisonne en fourchettes. Monte Carlo forward sur clôtures Apple : dérive et vol avant 2023, bande 5e–95e vs hold-out 2023. English version.
Monte Carlo forward vs MCMC
| Outil | Question |
|---|---|
| Monte Carlo ici | « Quelle ampleur de swing sous GBM simple ? » |
| MCMC | « Quelle loi colle aux prix observés ? » |
Repo : AlgoETS/MarkokChainMonteCarlo.
Split train / hold-out
Couper au 2023-01-01, estimer rendements log sur train, simuler chemins.
Cœur de simulation
Rendements log → drift/vol → chocs gaussiens → exp(...).
Code complet : Medium.
Limites
Vol constante, pas de sauts, une seule action — pas un signal d’achat.
Bilan
Monte Carlo = largeur du risque modèle ; backtest = PnL d’une règle.