Caddy déjà à la maison pour Home Assistant ; ici la version bordure AWS : EC2, HTTPS auto, logs JSON vers CloudWatch, shipper Python en cron, Lambda pour requêtes Insights. English version.
Étape 1 — EC2 + Caddy
Instance nano/micro, ports 22/80/443, install yum depuis dépôt Caddy. Caddyfile avec snippets log_site et reverse_proxy. sudo caddy reload.
Étape 2 — CloudWatch
Logs rotatifs sous /home/ec2-user/caddy/logs/, script boto3 put_log_events, cron nocturne.
Étape 3 — Lambda / Insights
Exemple IP distinctes :
fields @message
| parse @message /"remote_ip": "(?<remote_ip>[^"]+)"/
| stats count_distinct(remote_ip) as unique_ip by remote_ip
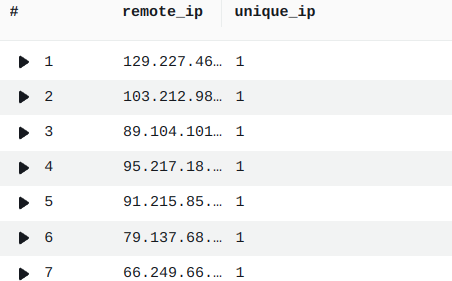
Bilan
Visibilité reverse-proxy sans SaaS cher — avec délai cron accepté.